The Power of Pre-Mortems in Software Development
The software post-mortem is well known. It’s a standard best practice that really marks the end of any software project. It also fits in well with the Agile manifesto, specifically the retrospective - always be reflecting, always be improving.
Post-mortems are usually only conducted when things go wrong. And of course they should. Wrong is bad for business. Outages and issues cause your company to lose money and erode both your user brand and engineering brand.
What exactly is a software failure?
A software failure is simply anything that prevents your users from doing the thing they wanted to do (or you wanted them to do). It’s easy to recall stories of some backend system (like AWS itself) falling over or GitLab’s 2017 DB outage causing massive issues. But it’s also things like missing or just bad language translations confusing a user.
If a user can’t do what they want to do - it’s a failure.
Failures occur when a change happens to your system. Most often, it’s a config change, but really it’s any change made by a human. We know this because failures go down when developers are not working. And since we can’t really just stop working, we need to understand mistakes and issues are inevitable. We just need to reduce and not repeat our mistakes - hence the power of the post-mortem.
It’s unfortunate such a great practice ends up happening after an issue occurs.
Enter the Pre-Mortem
The software pre-mortem is a practice where a team imagines and predicts failures or issues that could occur in order to capture any learnings before anything actually bad happens. The Harvard Business Review suggests an exercise like this can increase “the ability to correctly identify reasons for future outcomes by 30%.”
Pre-Mortem Benefits
The main benefit of this practice is to identify potential issues and their likelihood, and of course pre-emptively fix them. Is it reasonable to think you can find and fix everything? Absolutely not. But there are more benefits from this practice, including:
- It’s a best in class opportunity to uplevel the knowledge of the entire team
- All developers get to consider all the areas that could go wrong - accelerating their learning
- Getting a diverse group discussing issues ensures better coverage than just the limited few architects.
- Allows the team extra time to laser focus on the actual issue
- Post-mortems should be blameless, but I’ve seen people succumb to pressure to quickly find an answer.
- Pre-mortems occur when nothing bad has happened giving you time to find and fix the right cause.
- Fosters a culture of encouraging contrarian opinions and avoiding groupthink.
- It’s a fun activity that bonds the team and develops team trust
- It’s quick, easily understandable, and requires very little prep work.
When to do it?
- Before any major software release (ie the team’s been working on a large project for 9 months and it’s about to go live)
- Proactively throughout the year, like quarterly.
How to run a Pre-Mortem
It’s simple. Gather all the team members (and maybe a few outsiders) into a room. Facilitate a discussion around what could go wrong. Take notes and rank items in terms of likelihood.
Conclusion
“The difference between average programmers and excellent developers is not a matter of knowing the latest language or buzzword-laden technique. Rather, it can boil down to something as simple as not making the same mistakes over and over again.” — Mike Gunderloy
Now go make the Pre-Mortem a standard practice in your team today!
Appendix
What types of issues should you be considering?
Here’s a (non-exhaustive) list of areas I’ve used which may help.
- Scale / load, can each downstream system take the load we expect, what if it’s higher than we expect, does it gracefully degrade? Do we have enough physical machines to host our traffic, and what’s our plan B if we hit our limits? Have we run our own load test?
- Security - what would a hacker exploit in our system. What if some bad actor wants to put an endpoint under load, do we rate limit? Do we expose an endpoint that could be used to validate stolen email addresses? Leaking user data or PII, DOS attacks, XSS, abusing our comm systems, CSRF issues?
- Speed (server time, latency, payload size)
- Machine limits - CPU, memory, I/O, thread limits, memory leaks
- Data Center failure
- Visual / UX (JS, CSS bugs, no JS)
- Underperforming variant
- Business Metrics - would we know if this new project was successful before we do deep data dives and involve others? Do we have real-time monitoring to give us some insight in near-real time? What metrics do we care about?
- Walk through user scenarios - what if they aren’t logged in, what if they use https, what if they are international, different language set? Are we logging this info? Have we considered:
- Country
- Mobile Device platform
- Browser
- Language, are translations working
- Guest / logged-in
- Accessibility, JS enabled / disabled
- Realities of human software engineering
- What if a critical team member is on vacation? Are there runbooks?
- What if another team changes code that changes our assumptions? Do we monitor reviews / check-ins for the code we own or care about?
- When an issue occurs (and it will)
- Alerting - Do we have enough monitoring or alerting to catch it faster?
- Logging - Do we have proper logging in place to swiftly troubleshoot it?
You May Also Enjoy
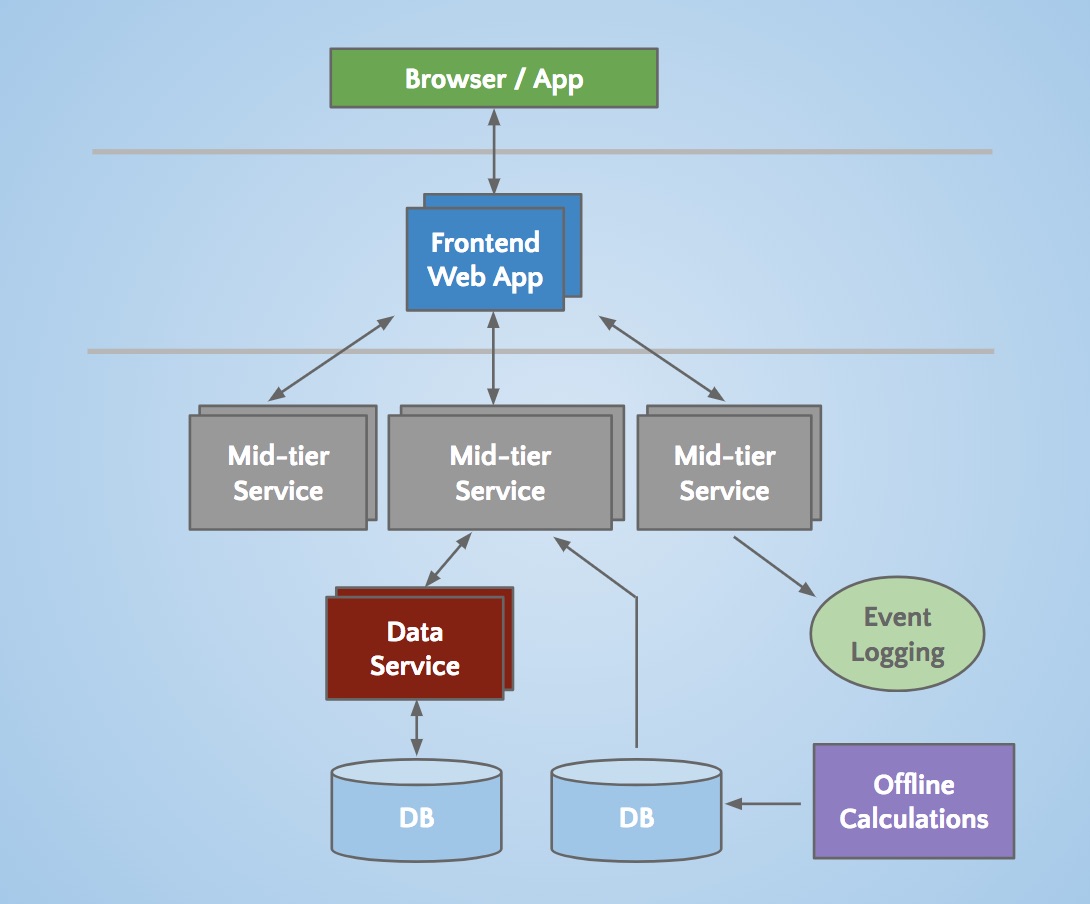
So, You Want to Move to Microservices?As I reflected back on my time at LinkedIn, I put together a brief history of its scaling story. We had done the (now) classi... |
Code Reviews by Phase and ExpectationsCode reviews are amazing for many reasons. And everyone on the team should contribute. Interestingly, the behavior of an engi... |